안녕하세요~ 박성호입니다!
저번글에서 예고한 바와 같이 DBSCAN 개념과 실습 코드를 갖고 왔습니다.
□ DBSCAN이란?
DBSCAN (Density-Based Spatial Clustering of Application with Noise)은 아주 유용한 군집 알고리즘입니다.
DBSCAN의 주요 장점은 클러스터의 개수를 미리 지정할 필욕 없다는 점입니다.
DBSCAN은 특성 공간에서 가까이 있는 데이터가 많아 붐비는 지역의 포인트를 찾습니다. 이런 지역을 특성 공간의 밀집 지역(Dense Region)이라고 합니다.
DBSCAN의 아이디어는 데이터의 밀집 지역이 한 클러스터를 구성하며 비교적 비어있는 지역을 경계로 다른 클러스터와 구분된다는 것입니다.
밀집 지역에 있는 포인트를 핵심 샘플 (또는 햄심 포인트)라고 하며 다음과 같이 정의합니다. DBSCAN에는 여러 파라미터중 2개의 파라미터, min_samples와 eps가 군집에 큰 영향을 미칩니다.
한 데이터 포인트에서 eps거리안에 데이터가 min_samples 개수만큼 들어 있으면 이 데이터 포인트를 핵심 샘플로 분류합니다. eps보다 가까운 핵심 샘플은 DBSCAN에 의해 동일한 클러스터로 합쳐집니다.
DBSCAN은 시작할 때 무작위로 포인트를 선택합니다. 그런 다음 그 포인트에서 eps거리안의 모든 포인트를 찾습니다.
만약 eps거리안에 있는 포인트가 min_samples보다 적다면 그 포인트는 어떤 클래스엗 속하지 않은 잡음(Noise)으로 레이블합니다.
eps거리안에 min_samples보다 많은 포인트가 있다면 그 포인트는 핵심 샘플로 레이블하고 새로운 클러스터 레이블을 할당합니다. 그런 다음 그 포인트의 (eps거리안의) 모든 이웃을 살핍니다.
만약 어떤 클러스터에도 아직 할당되지 않았다면 바로 전에 만든 클러스터 레이블을 할당합니다. 만약 핵심 샘플이면 그 포인트의 이웃을 차례로 방문합니다.
이런 식으로 계속 진행하여 클러스터는 eps거리안에 더 이상 핵심 샘플이 없을 때까지 자라납니다. 그런 다음 아직 방문하지 못한 포인트를 선택하여 같은 과정을 반복합니다.
결국 DBSCAN의 포인트 종류는 3가지입니다. 핵심포인트, 경계포인트, 잡음포인트입니다.
DBSCAN을 한 데이터셋에 여러번 실행하면 핵심포인트의 군집은 항상 같고 매번 같은 포인트를 잡음으로 레이블합니다. 그러나 경계 포인트는 한개이상의 클러스터 핵심 샘플의 이웃일 수 있습니다.
그렇기때문에 경계포인트가 어떤 클러스터에 속할지는 포인트를 방문하는 순서에 따라 달라집니다. 보통 경계 포인트는 많지않으며 포인트 순서때문에 받는 영향도 적어 중요한 이슈는 아닙니다.
from sklearn import cluster
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# 데이터 생성
X, y = make_blobs(random_state=0, n_samples=12)
# 생성된 데이터 출력
X, y
>>> (array([[ 3.54934659, 0.6925054 ],
[ 1.9263585 , 4.15243012],
[ 0.0058752 , 4.38724103],
[ 1.12031365, 5.75806083],
[ 1.7373078 , 4.42546234],
[ 2.36833522, 0.04356792],
[-0.49772229, 1.55128226],
[-1.4811455 , 2.73069841],
[ 0.87305123, 4.71438583],
[-0.66246781, 2.17571724],
[ 0.74285061, 1.46351659],
[ 2.49913075, 1.23133799]]),
array([1, 0, 2, 0, 0, 1, 1, 2, 0, 2, 2, 1]))# 산점도, index 라벨링
plt.plot(X[:,0],X[:,1],'ro')
for i in range(X.shape[0]):
plt.text(X[i,0], X[i,1], str(i),)
# 산점도, index 라벨링
plt.plot(X[:,0],X[:,1],'ro')
for i in range(X.shape[0]):
plt.text(X[i,0], X[i,1], str(i),)
클러스터 레이블 :
>>> [-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1]mglearn.plots.plot_dbscan()
이 그래프에서는 클러스터에 속한 포인트는 색을 칠하고 잡음 포인트는 하얀색으로 남겨집니다. 핵심 샘플은 크게 표시하고 경계 포인트는 작게 나타났습니다.
- eps를 증가시키면 (왼쪽에서 오른쪽으로) 하나의 클러스터에 더 많은 포인트가 포함됩니다. 이는 클러스터를 커지게 하지만 여러 클러스터를 하나로 합치게도 만듭니다.
- min_samples를 키우면 (위에서 아래로) 핵심 포인트 수가 줄어들며 잡음 포인트가 늘어납니다.
plt.style.use('dark_background')
mglearn.plots.plot_dbscan()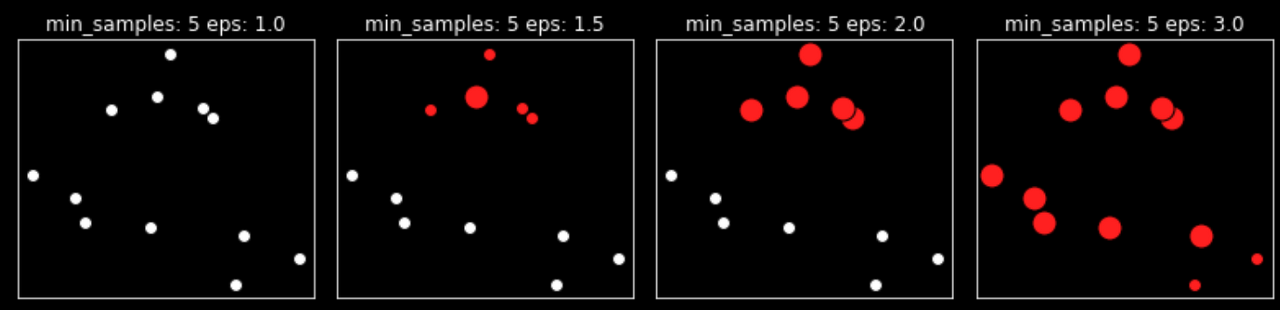
DBSCAN의 파라미터 eps는 가까운 포인트의 범위를 결정하기 때문에 더 중요합니다.
eps를 매우 작게 하면 어떤 포인트도 핵심포인트가 되지 못하고, 모든 포인트가 잡음 포인트가 될 수 있습니다.
eps를 매우 크게 하면 모든 포인트가 단 하나의 클러스터에 속하게 됩니다.
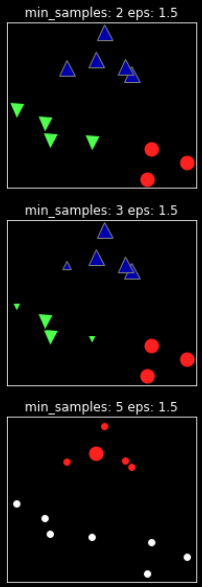
DBSCAN의 두번째 파라미터 min_samples는 덜 조밀한 지역에 있는 포인트들이 잡음 포인트가 될 것인지, 하나의 클러스터가 될 것인지를 결정하는 데 중요한 역할을 합니다. min_samples를 늘리면 min_samples의 수 보다 작은 클러스터들은 잡음 포인트가 됩니다.
그러므로 min_samples는 클러스터의 최소 크기를 결정합니다.
□ DBSCAN 실습
이제 DBSCAN을 실습해보도록 하겠습니다.
저번 글에서 AgglomerativeClustering는 데이터와 클러스터간의 거리를 기반으로 군집을 시키기때문에 한계점으로 two_moons dataset의 noise가 0.1일때는 군집을 못하는 모습을 보였습니다.
from sklearn.cluster import KMeans
from sklearn.cluster import AgglomerativeClustering
from sklearn.cluster import DBSCAN
plt.figure(figsize=(15,10))
X_m,y_m = make_moons(n_samples=300, noise=0.1, random_state=0)
agg_m = AgglomerativeClustering(n_clusters=2, linkage='single')
assignmeant_m = agg_m.fit_predict(X_m)
mglearn.discrete_scatter(X_m[:,0],X_m[:,1], assignmeant_m, s=20)
하지만 DBSCAN은 데이터의 밀도를 기반으로 군집을 시키기 때문에 보시는 바와 같이 군집을 잘 해냅니다.
plt.figure(figsize=(15,10))
dbscan_m = DBSCAN(eps=0.17)
clusters_m = dbscan_m.fit_predict(X_m)
mglearn.discrete_scatter(X_m[:,0],X_m[:,1],clusters_m, s=20, markeredgewidth=2 ,alpha=0.7)
또한 다른 데이터셋도 군집을 시켜보았습니다.
fig, axes = plt.subplots(1,5, figsize=(40,10))
agg_c = AgglomerativeClustering(n_clusters=2, linkage='single')
assignmeant_c = agg_c.fit_predict(X_c)
mglearn.discrete_scatter(X_c[:,0],X_c[:,1], assignmeant_c, s=20 ,ax=axes[0])
agg_m = AgglomerativeClustering(n_clusters=2, linkage='single')
assignmeant_m = agg_m.fit_predict(X_m)
mglearn.discrete_scatter(X_m[:,0],X_m[:,1], assignmeant_m, s=20 ,ax=axes[1])
agg_trm = AgglomerativeClustering(n_clusters=3, linkage='complete')
assignmeant_trm = agg_trm.fit_predict(X_trm)
mglearn.discrete_scatter(X_trm[:,0],X_trm[:,1], assignmeant_trm , s=20 ,ax=axes[2])
agg_r = AgglomerativeClustering(n_clusters=3)
assignmeant_r = agg_r.fit_predict(X_r)
mglearn.discrete_scatter(X_r[:,0],X_r[:,1], assignmeant_r, s=20 ,ax=axes[3])
agg_b = AgglomerativeClustering(n_clusters=3)
assignmeant_b = agg_b.fit_predict(X_b)
mglearn.discrete_scatter(X_b[:,0],X_b[:,1], assignmeant_b, s=20 ,ax=axes[4])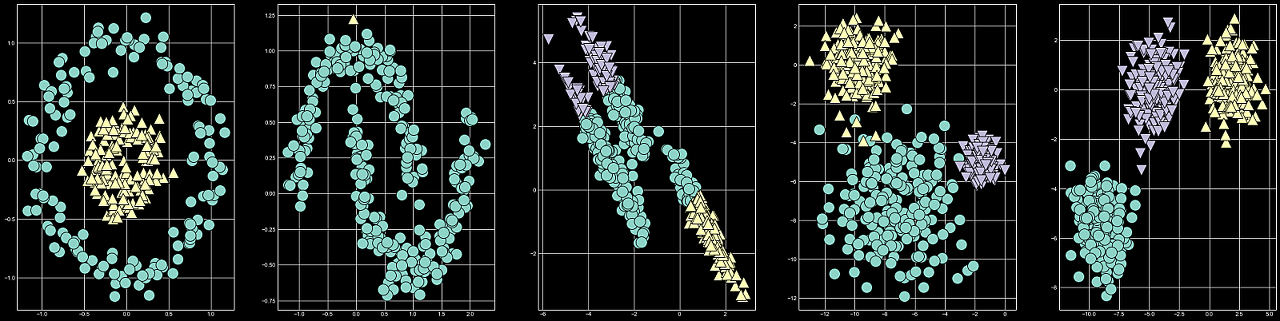
AgglomerativeClustering는 Circles[첫번째]와 분산이 다른 blobs[네번째], blobs dataset[다섯번째], 만 군집시킨 모습입니다. 그렇다면 DBSCAN은 어떨까요?
fig, axes = plt.subplots(1,5, figsize=(35,10))
dbscan_c = DBSCAN(eps=0.243)
clusters_c = dbscan_c.fit_predict(X_c)
mglearn.discrete_scatter(X_c[:,0],X_c[:,1],clusters_c ,s=20, markeredgewidth=2 ,alpha=0.7, ax=axes[0])
dbscan_m = DBSCAN(eps=0.17)
clusters_m = dbscan_m.fit_predict(X_m)
mglearn.discrete_scatter(X_m[:,0],X_m[:,1],clusters_m, s=20, markeredgewidth=2 ,alpha=0.7, ax=axes[1])
dbscan_trm = DBSCAN(eps=0.43)
clusters_trm = dbscan_trm.fit_predict(X_trm)
mglearn.discrete_scatter(X_trm[:,0],X_trm[:,1],clusters_trm, s=20, markeredgewidth=2 ,alpha=0.7, ax=axes[2])
dbscan_r = DBSCAN(eps=1.9, min_samples=11)
clusters_r = dbscan_r.fit_predict(X_r)
mglearn.discrete_scatter(X_r[:,0],X_r[:,1], clusters_r, s=20, markeredgewidth=2 ,alpha=0.7, ax=axes[3])
dbscan_b = DBSCAN(eps=1.1, min_samples=4)
clusters_b = dbscan_b.fit_predict(X_b)
mglearn.discrete_scatter(X_b[:,0],X_b[:,1],clusters_b, s=20 ,alpha=0.7, ax=axes[4])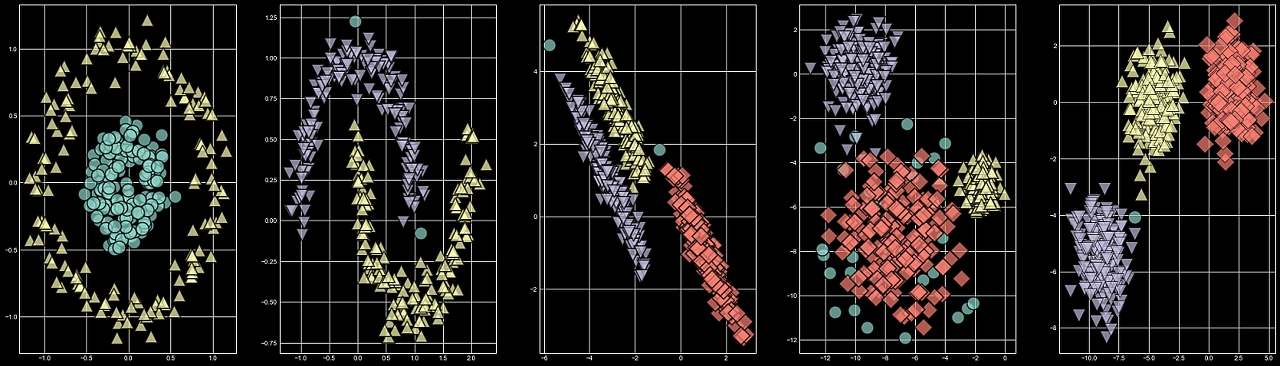
[네번째 그림] 분산이 다른 blobs dataset에서는 조금 성능이 떨어지는 것 같긴 하지만, 다른 데이터셋에서는 성능이 좋아보입니다.
이렇게 K-MEANS와 AgglomerativeClustering에 이어 DBSCAN까지 군집화를 해보았고 이러한 결과를 종합하여 시각화하면서 글을 마치겠습니다.
K-MEANS와 AgglomerativeClustering 코드는 이전 글을 참고하시길 바라겠습니다.
f, axes = plt.subplots(3, 5)
plt.style.use('dark_background')
f.set_size_inches((30, 15))
plt.subplots_adjust(wspace = 0.3, hspace = 0.3)
ax = plt.gca()
bounds = ax.get_xbound()
###### [ DBSCAN ] ##################
axes[0, 0].scatter(X_c[:,0],X_c[:,1], c=clusters_c, cmap="coolwarm", edgecolor='black')
axes[0, 0].set_title("DBSCAN_Circle", bbox=dict(facecolor='blue', alpha=0.5), fontdict={'size':15})
axes[0, 1].scatter(X_m[:,0],X_m[:,1], c=clusters_m, cmap="Set2", edgecolor='black')
axes[0, 1].set_title("DBSCAN_Moons", bbox=dict(facecolor='blue', alpha=0.5), fontdict={'size':15})
axes[0, 2].scatter(X_trm[:,0],X_trm[:,1], c=clusters_trm, cmap="tab10", edgecolor='black')
axes[0, 2].set_title("DBSCAN_Transform", bbox=dict(facecolor='blue', alpha=0.5), fontdict={'size':15})
axes[0, 3].scatter(X_r[:,0],X_r[:,1], c=clusters_r, cmap="plasma", edgecolor='black')
axes[0, 3].set_title("DBSCAN_Blobs", bbox=dict(facecolor='blue', alpha=0.5), fontdict={'size':15})
axes[0, 4].scatter(X_b[:,0],X_b[:,1], c=clusters_b, cmap="rainbow", edgecolor='black')
axes[0, 4].set_title("DBSCAN_Blobs2", bbox=dict(facecolor='blue', alpha=0.5), fontdict={'size':15})
###### [ KMEANS ] #################
axes[1, 0].scatter(X_c[:,0],X_c[:,1], c=y_pred_c, cmap="coolwarm", edgecolor='black')
axes[1, 0].set_title("K-MEANS_Circle", bbox=dict(facecolor='red', alpha=0.5), fontdict={'size':15})
axes[1, 1].scatter(X_m[:,0],X_m[:,1], c=y_pred_m, cmap="Set2", edgecolor='black')
axes[1, 1].set_title("K-MEANS_Moons", bbox=dict(facecolor='red', alpha=0.5), fontdict={'size':15})
axes[1, 2].scatter(X_trm[:,0],X_trm[:,1], c=y_pred_trm, cmap="tab10", edgecolor='black')
axes[1, 2].set_title("K-MEANS_Transform", bbox=dict(facecolor='red', alpha=0.5), fontdict={'size':15})
axes[1, 3].scatter(X_r[:,0],X_r[:,1], c=y_pred_r, cmap="plasma", edgecolor='black')
axes[1, 3].set_title("K-MEANS_Blobs", bbox=dict(facecolor='red', alpha=0.5), fontdict={'size':15})
axes[1, 4].scatter(X_b[:,0],X_b[:,1], c=y_pred_b, cmap="rainbow", edgecolor='black')
axes[1, 4].set_title("K-MEANS_Blobs2", bbox=dict(facecolor='red', alpha=0.5), fontdict={'size':15})
###### [ Agglomerative ] #################
axes[2, 0].scatter(X_c[:,0],X_c[:,1], c=assignmeant_c, cmap="coolwarm", edgecolor='black')
axes[2, 0].set_title("AgglomerativeClustering_Circle", bbox=dict(facecolor='green', alpha=0.5), fontdict={'size':15})
axes[2, 1].scatter(X_m[:,0],X_m[:,1], c=assignmeant_m, cmap="Set2", edgecolor='black')
axes[2, 1].set_title("AgglomerativeClustering_Moons", bbox=dict(facecolor='green', alpha=0.5), fontdict={'size':15})
axes[2, 2].scatter(X_trm[:,0],X_trm[:,1], c=assignmeant_trm, cmap="tab10", edgecolor='black')
axes[2, 2].set_title("AgglomerativeClustering_Transform", bbox=dict(facecolor='green', alpha=0.5), fontdict={'size':15})
axes[2, 3].scatter(X_r[:,0],X_r[:,1], c=assignmeant_r, cmap="plasma", edgecolor='black')
axes[2, 3].set_title("AgglomerativeClustering_Blobs", bbox=dict(facecolor='green', alpha=0.5), fontdict={'size':15})
axes[2, 4].scatter(X_b[:,0],X_b[:,1], c=assignmeant_b, cmap="rainbow", edgecolor='black')
axes[2, 4].set_title("AgglomerativeClustering_Blobs2", bbox=dict(facecolor='green', alpha=0.5), fontdict={'size':15})
이상으로 [Python/ML] DBSCAN Clustering 을 마치도록 하겠습니다..
오늘도 긴 글 읽어주셔서 대단히 감사드립니다.
'Data Park > Python' 카테고리의 다른 글
| [Python/ML] SVR (Support Vector Regression) (0) | 2023.02.08 |
|---|---|
| [Python/ML] Agglomerative Hierarchical Clustering (계층적 군집화) (2) | 2023.01.28 |
| [Python/ML] K-MEANS Clustering (0) | 2023.01.27 |
| [Python/ML] K-NN (K-Nearest Neighbors) (0) | 2023.01.10 |
| [Python/ML] SVM (Support Vector Machine) (0) | 2023.01.04 |



